Overview
What LiveRL is and how the pieces fit together
LiveRL trains real coding agents with online reinforcement learning — on real repositories. The policy improves by repeatedly attempting real SWE tasks inside sandboxes and being rewarded for the patches that actually make the tests pass.
Where supervised fine-tuning imitates known-good trajectories, LiveRL optimizes the policy directly against the environment's own reward signal, in a closed self-improvement loop: the agent drives the same model it is training, the verifier grades the result, and the trainer updates the weights.
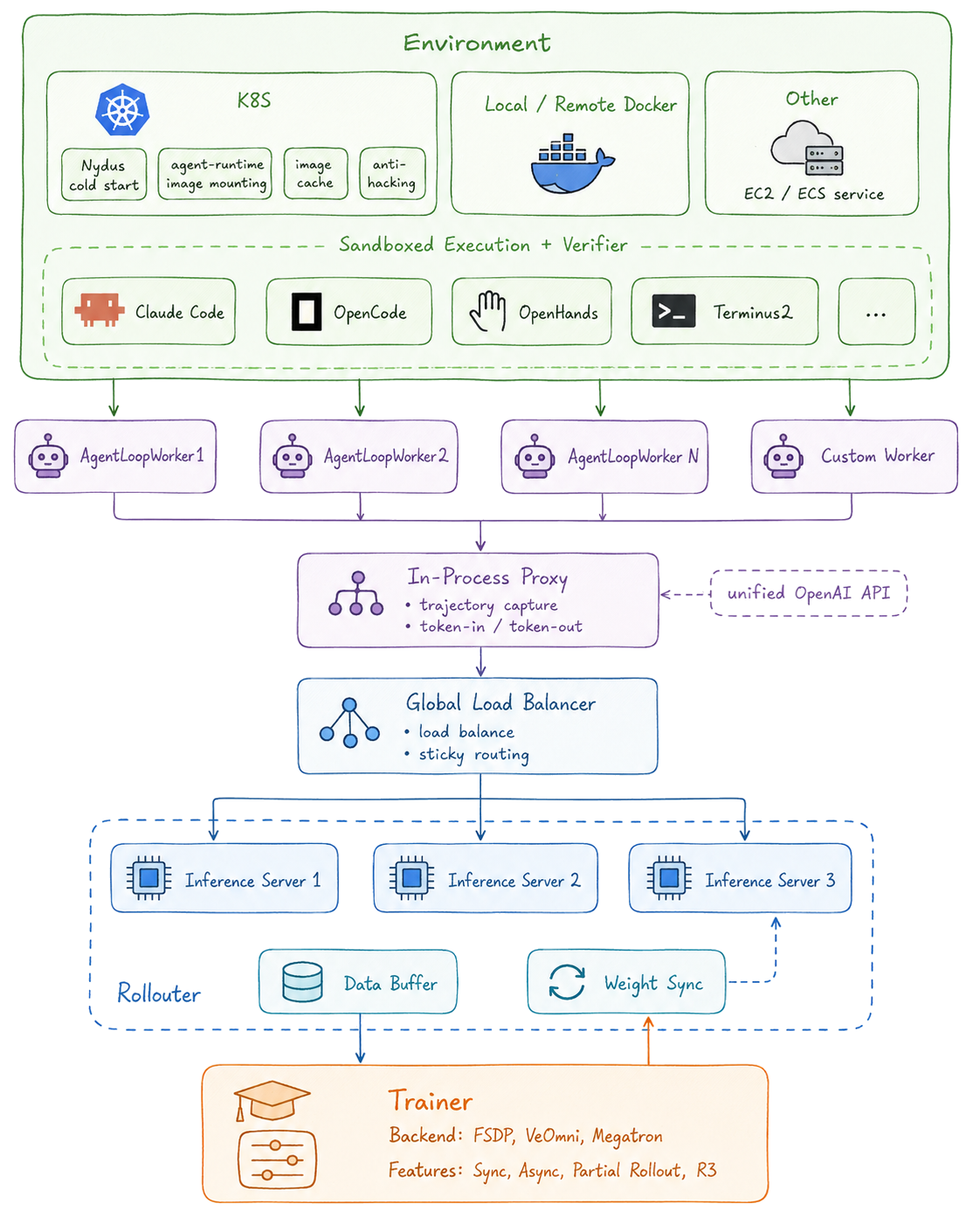
The loop
Each layer below has its own page in Architecture:
- Environment — each task runs in a fresh sandbox (a Kubernetes pod, a local/remote Docker container, or an EC2/ECS service) with sandboxed execution plus the task's own verifier. A coding-agent scaffold — Claude Code, OpenCode, OpenHands, Terminus 2, … — drives the model through the task.
- AgentLoopWorkers run the scaffolds concurrently and capture each rollout.
- In-Process Proxy fronts every worker with a single, unified OpenAI/Anthropic API — it captures the trajectory (token-in / token-out) and forwards each call onward. No standalone LiteLLM.
- Global Load Balancer spreads requests across inference replicas with sticky, per-session routing.
- Rollouter — a pool of vLLM inference servers serves the policy, streams completed rollouts into a Data Buffer, and receives Weight Sync updates.
- Trainer — verl consumes the buffer, computes advantages, and updates the actor (PPO / GRPO / GSPO), then syncs new weights back to the rollouter for the next round.
What makes LiveRL different
- The reward is the test suite, not a model. Each task's own verifier runs inside the sandbox and the reward is the literal pass/fail — so the policy is optimized on "did it actually fix the bug", with no reward-model drift to hack.
- It trains the agent, not a single turn. Optimization runs over full multi-turn rollouts of a real coding agent (PPO / GRPO / GSPO), so the model learns to plan, edit, run tests, and recover — not just emit one good completion.
- The agent drives the model it is training. One unified in-process proxy
serves every scaffold (Claude Code over Anthropic
/v1/messages, OpenHands / OpenCode / Terminus over OpenAI/v1/chat/completions) from the self-served policy, and captures the exact token-level trajectory used for the update — no off-policy mismatch, no separate logging service. - Real sandboxes, at scale. Rollouts run as real Harbor containers — Kubernetes in production, local/remote Docker for a minimal setup — with cold-start, image caching, and anti-reward-hacking built in.
- Sync for cheap, async for scale. Start on one 8×GPU host with a synchronous loop; scale out to a decoupled rollout/trainer cluster with partial rollout and R3 when you need it.
- Bring your own backend. The trainer runs on FSDP, VeOmni, or Megatron — dense or large-MoE policies, same loop.
Where to go next
- Getting Started — prerequisites and your first training run
- Architecture — a page per layer of the diagram above
- Core Concepts — trials and rewards, the verl loop, terminology
- Run Training — launch, monitor, and where outputs land
- Dashboard — watch reward, KL, MFU, and response length live
- Reference — the launch-script configuration surface