Architecture
Architecture
The layers of the LiveRL framework, one page each
LiveRL is a pipeline from a sandboxed coding task to a weight update. Requests flow down the stack (agent → proxy → load balancer → inference servers) and data + weights flow back up (rollouts → buffer → trainer → weight sync). Each layer below has its own page.
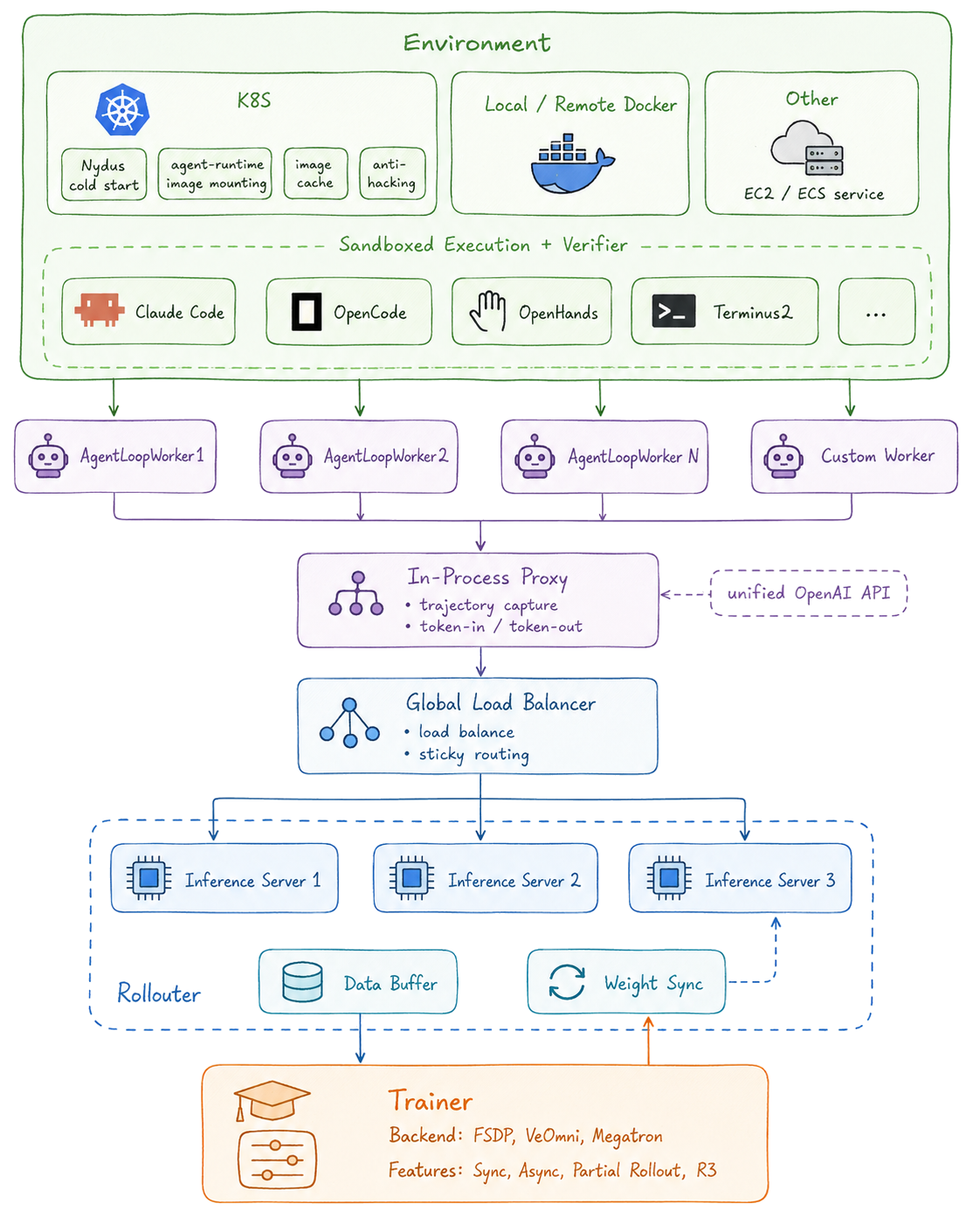
The layers
| Layer | Role |
|---|---|
| Environment | Sandboxed execution + verifier; the coding-agent scaffolds and the backends (K8s / Docker / EC2-ECS) that run them |
| AgentLoopWorkers | Run the scaffolds concurrently, one trial each, and capture the rollout |
| In-Process Proxy | One unified OpenAI/Anthropic API in front of the policy; captures token-level trajectories |
| Global Load Balancer | Spreads requests across inference replicas with sticky, per-session routing |
| Rollouter | The vLLM inference-server pool, the rollout data buffer, and weight sync |
| Trainer | verl actor on FSDP / VeOmni / Megatron; PPO / GRPO / GSPO; sync, async, partial rollout, R3 |
How a step flows
- The trainer samples a batch of tasks and hands them to the AgentLoopWorkers.
- Each worker launches a scaffold inside an Environment sandbox and drives it through the task; every model call goes through the In-Process Proxy.
- The proxy routes the call through the Global Load Balancer to a vLLM replica in the Rollouter, and records the exact tokens for training.
- When the trial finishes, the verifier scores it; the completed rollout lands in the Data Buffer.
- The Trainer consumes the buffer, computes advantages, updates the actor, and pushes new weights back to the rollouter via Weight Sync — then the next step begins.